Search the Community
Showing results for tags 'compile block'.
Found 2 results
-
Hi, I've just got a question about compile blocks. I'm working on a relatively simple process that I need to run on extremely heavy data sets (groom curves), and I've noticed something odd. I need to do a check on each curve, and for reasons I need to do it on every curve in isolation so I'm putting my loop inside a compile block, If I loop over 100'000 curves and run this process then I get extremely fast results for the first 10'000 or so curves, however after about the halfway point I see my CPU usage drops right off and instead of seeing it calculate hundreds of curves per second it's down to 10-20 curves per second. It calculates the first half of the data set in about 4 mins but takes 30 mins to do the second half! At first I thought that this was due to the data set getting progressively heavier, however if that was true I would expect the CPU usage to remain high, despite the progress slowing down? I also had a go at randomising the sort order too, to see if that changed the result and it was the same. So I guess my question is this: What factors, apart from the size of the data-set could cause a compiled block process to slow down over time? Any insights are very welcome! Thanks in advance! M
-
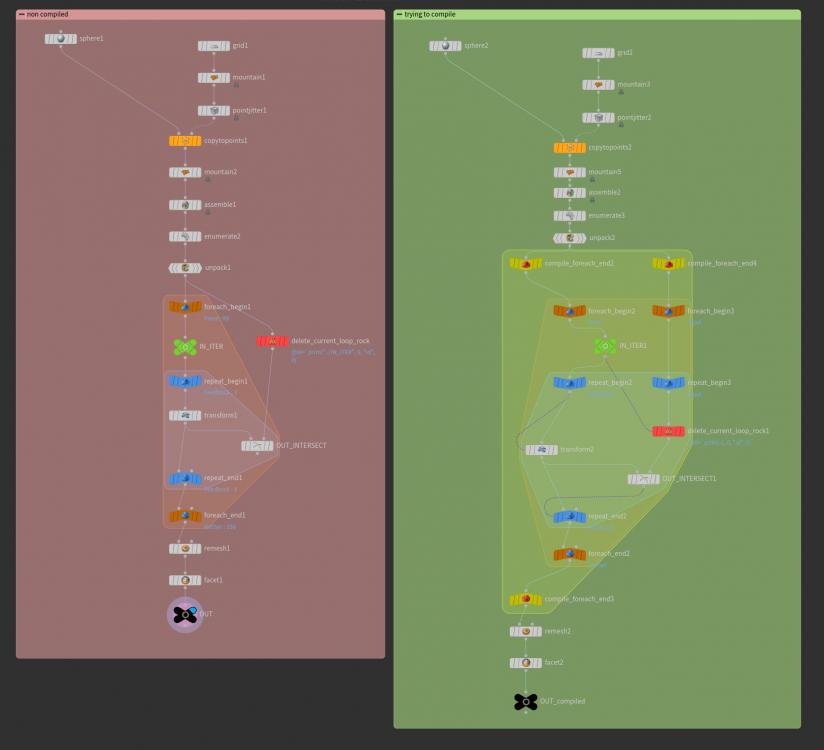
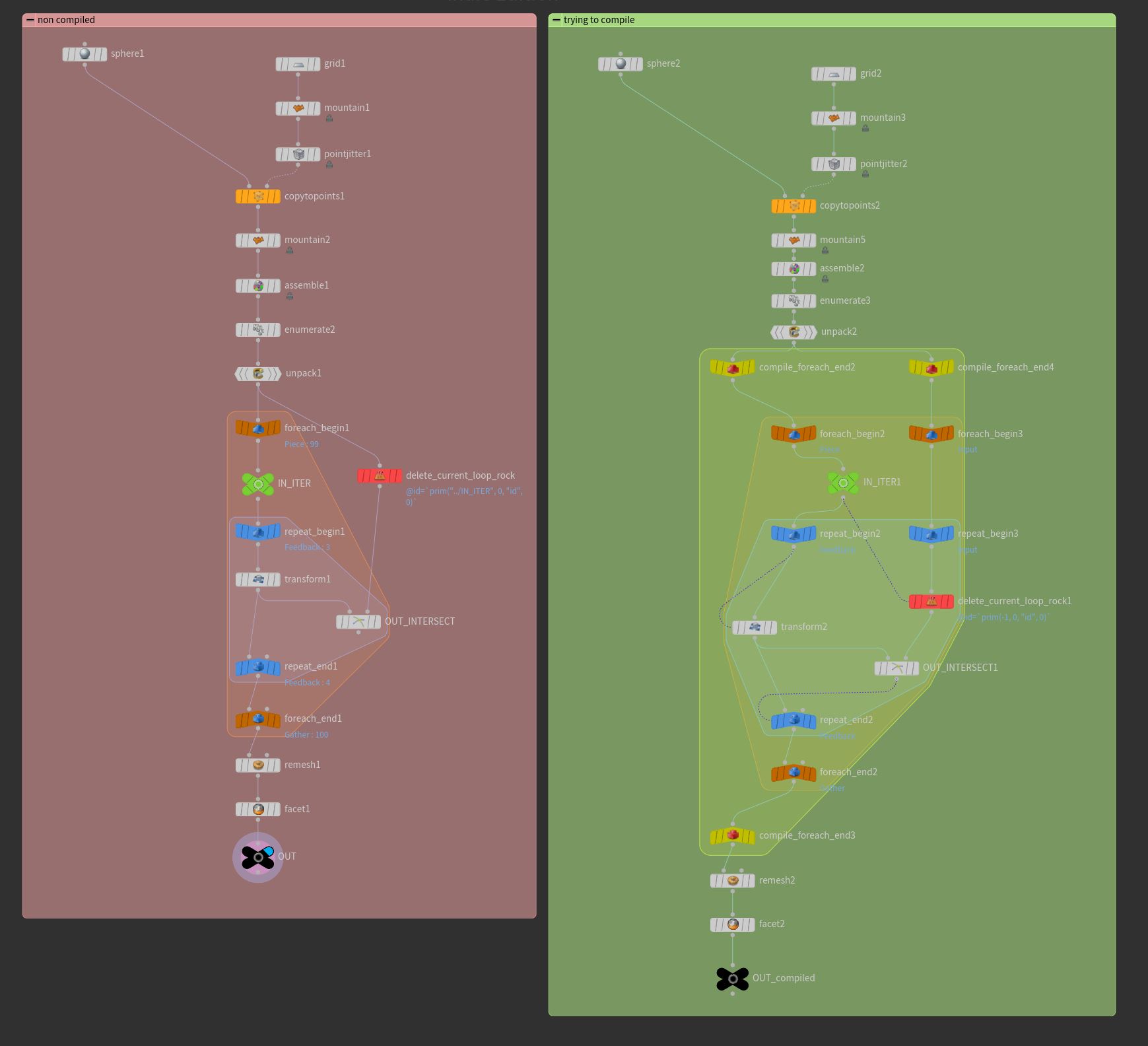
 Hi there! I'm trying to implement a compile block in this intersection analysis bellow (see example attached) At the left you will find a single thread setup and at right the multithread version. I'm trying to find a way to make the multicore setup to work. I've already seen the compile SOPs masterclass, but I couldn't find an answer. The STOP CONDITION seems to be unsupported until the date of the masterclass, but even disablying it, still not working. https://vimeo.com/222881605 I'm doing a project with a lot of this kind of work and I'd like to improve the processing time. Does anyone know what I'm doing wrong? Thanks! Cheers! Marco intersection_analysis_01.hiplc
Hi there! I'm trying to implement a compile block in this intersection analysis bellow (see example attached) At the left you will find a single thread setup and at right the multithread version. I'm trying to find a way to make the multicore setup to work. I've already seen the compile SOPs masterclass, but I couldn't find an answer. The STOP CONDITION seems to be unsupported until the date of the masterclass, but even disablying it, still not working. https://vimeo.com/222881605 I'm doing a project with a lot of this kind of work and I'd like to improve the processing time. Does anyone know what I'm doing wrong? Thanks! Cheers! Marco intersection_analysis_01.hiplc