

Adam Ferestad
-
Posts
271 -
Joined
-
Last visited
-
Days Won
3
2 Followers


Recent Profile Visitors
5,385 profile views










Adam Ferestad's Achievements
")





-
Shading based on another object?
Adam Ferestad replied to Adam Ferestad's topic in General Houdini Questions
Occlusion might work, but it only works if the other shape has dimension. I cannot pull from single points or curves with it. -
I don't do a lot with shaders, so I am not really sure what is possible and what is not, but I am attempting to sample details of one object from a shader applied to another. For instance, I place a curve on top of a grid, then have the shader sample the shortest distance to the curve to drive the shader. Is this possible? Or do I 100% have to use an obscenely dense geometry to sample it into an attribute so a shader can use it? I technically don't mind, but I was really hoping I could avoid that step and just have the shader do the work. I have tried using a nearpoint VOP in the shader, both with op:/obj/mySOP, exporting the points to disk and then targeting the file, as well as the same methods for using a point cloud. I know exactly how to do this with attributes on the mesh, it would just be cleaner to be able to do it as a shader.
-
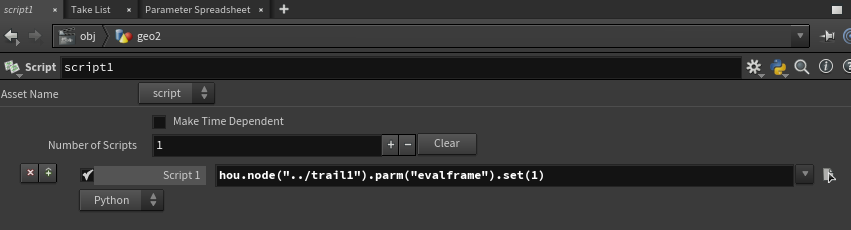
If that is the reason you are doing this, then you just need to setup an external editor and target VS. The method here is MUCH more about actually hacking around a bit to get external libraries and larger projects working within the interface. I personally was doing this because I needed to test a standalone package and it ended up being easier to make an HDA that could call it on a button instead of having to keep calling it in a console window, but the end goal was a standalone process that was being run without Houdini open. There are definitely use cases for what I did other than that, but if you just want to edit in a different editor, there are other ways. The only downside of setting up the external editor is that it blocks on opening so you can't mess around in Houdini until you are done. You can also try using a Script node. I tested it out and I think it will work for what you want to do just fine, since you only want to hit a button with it. This is tested and works. Whenever the node cooks, that tick box gets ticked. Simple and straight to the point. Judging by your image, you will probably want something like: list(map(lambda x: x[0].pressButton(), map(lambda y: y.globParms("reload"), hou.node(".").parent().glob("Test*")))) This will execute from left to right, first finding all nodes in the parent of the script node whose names start with "Test", then finding all reload parameters on those nodes, then pressing all of the buttons on them. I even tested it and it does indeed execute the code on each 'reload' parm that is found.
-
The way I had built it, the python you have in the python node was in the scripts of an HDA. The HDA had a button on it that executed the callback. hou.phm() only works on an HDA actually, so what you should need to do is put the code you have in the Python node directly into the Post Render Script and take out the callback def in favor of just calling GE.reloadNode() directly.
-
@Alain2131 I am attempting to get a VFL file written which will allow me to utilize this method. I knew how fast and easy it would have been in VEX, but unfortunately there is no good go between for the languages and the Hython restriction is a rock solid one. Eventually we may build a C++ DLL for it from the HDK, but for the time being we are using our app to interface directly with Hython, so it has to be in Hython or accessible from Hython. Unfortunately there are no verbs available which can utilize VEX, so the only option is hou.runVex() and compiling my own vex file to encapsulate the primpoints() VEX function. I have attempted, and failed. I cannot seem to figure out how to type the object right to be able to pass the HOM code, which doesn't surprise me as it is a Python object. I could possibly pass the file name, but loading and unloading files from memory to extract int lists on single prims seems woefully inefficient.
-
This is an interesting result, and I will have to examine things. It is imperative that it is implemented within Hython. The final functionality is going to call Hython from outside Houdini and use it to manage data. The code has to be able to be entirely within a .py library set. I am wondering if I could implement this using the hou.runvex() function. Unfortunately I have done literally 0 vex compiling and would need to figure that out. If I could do that and see these sorts of improvements in my code, then I would be attempting backflips.
-
Well, I'm glad that things are solved. I'm still curious about the project though. What you have listed there works incredibly well actually int A == @ptnum%23; int B == @ptnum%16; int i=0; while(True) { i += (A==0 || B==0); if(i>100000000 || @ptnum == npoints(0)-1) { break; } } If it isn't apparent, if statement in the while loop is solely in existence to end the loop if things get out of hand to keep it from being infinite and locking up the computer. Always a good idea with while(true).
-
So I am working on a project which is requiring me to extract the point numbers from an arbitrary polygonal object. The most pythonic way to do what I am trying to do is this: geo = hou.Geometry() geo.loadFromFile(path/to/my/file.bgeo.sc) primPoints = [[pt.number() for pt in pr.points()] for pr in geo.prims()] I need to maintain the winding order and get it down to just the ints for the point numbers. I have profiled every function in this, and hou.Prim.points() is god awful slow, taking up 16 of 22 seconds on a 1.5M poly, 800k point file. I am trying to find a way to circumvent hou.Prim.points() but nothing is jumping out to me. I have even moved everything into Pandas, which does make working with the data and doing further transformations easier, but I have not gotten any performance increases as it still relies on calling hou.Prim.points() for every primitive. I have contemplated trying to use hou.Geometry.points() and calling hou.Point.prims() to go at it from the other direction, thinking that it might save me some time since the list of points is always shorter than the list of prims, but it loses the winding order, which I need for my use case. Said use case is parsing cached geometry into a custom format for optimized use elsewhere. I have been able to get the performance up to snuff on just about everything else, and will save even more time on later steps thanks to Pandas data management, but this singular step is so sluggish that it just about tanks the whole project. Literally everything else in the pipeline that I am developing is under 4-5 seconds/frame for huge geometry volumes in the pre-process step (which this is part of) and the final end of the process is so fast I'm not even going to talk about it. Literally just this is bogging things down in an untenable way. Pandas code for reference: import pandas as pd geo = hou.Geometry() geo.loadFromFile(path/to/my/file.bgeo.sc) primsSeries = pd.Series(data=geo.prims()) primsSeries = primsSeries.apply(hou.Prim.points) primsSeries = primsSeries.apply(lambda x: list(map(hou.Point.number, x))) The two take virtually identical amounts of time with the pure pythonic one being a couple seconds faster because it is doing the hou.Point.number in the same step as the list generation, whereas the Pandas code currently does it as a secondary step. I'm sure I could include it in the hou.Prim.points apply, but this was mostly separated for profiling to see where all of my speed was going. Does anyone out there have any idea how to bypass hou.Prim.points in this process in favor of something faster or am I 100% stuck?
-
I had a similar issue recently and this was how I got it working. It probably is way more than needed, but it works like a charm. You have to put the below on a default python module on the node you want to work with. Then load the reload.py as another python module. This code links the two. import importlib.util spec = importlib.util.spec_from_file_location("foo", "path/to/your/script.py") GE = importlib.util.module_from_spec(spec) spec.loader.exec_module(GE) def callback(): GE.foo() Then the callback is hou.phm().callback() in your case, you would use hou.node('path/to/your/node').phm().callback()
-
Ok, so "combining" is not a very good word to use when it comes to math concepts, as it can be extremely arbitrary. For ease of discussion, I am going to call what you are looking to do a function. It will have inputs and an output. You are looking to input the moduli, but a modulus is a function which is applied to a pair of numbers to yield the remainder if they were divided. This does not really make sense as an input, which I think is the reason you are struggling. I think getting a handle on what you want your inputs to actually be and your output to be would probably go a long way towards helping find the correct answer. You mention that you want to use the two moduli to increment the rotation of the initial velocity. What would that look like in your mind? Are you looking to transition between two vectors based on the moduli?
-
That is just for opening a hipfile from the python interface, be it a Hython console, python node, or executing a script with Hython from the command line. Once you have the scene loaded, as in the examples on that page, you can access all of the objects within it to process. I would suspect you aren't going to be needing to do this unless you are automating some pipeline stuff that needs to affect many files in succession and process them.
-
I am working to build a tool which contextualizes updates options in a multiparm block based on an option selected in the block itself. I have been able to get ahold of the information for which index in the multiparm everything is going and have been able to extract information just fine, but I cannot seem to update the UI. I really feel like I am just missing a function somewhere in the documentation. Right now I'm essentially doing this to update what I have now: def load(): node = hou.pwd() ptg = node.parmTemplateGroup() baseAttribs = ["list", "pulled", "in", "from", "elsewhere"] multiparm = hou.FolderParmTemplate("attrib", "Attrib Item", folder_type = hou.folderType.MultiparmBlock) collapsibleFolder = hou.FolderParmTemplate("settings#", "Settings", folder_type = hou.folderType.Collapsible) attribList = hou.MenuParmTemplate("root_attribs#", "Select Attribute", tuple(baseAttribs), menu_labels=tuple(baseAttribs), script_callback="hou.phm().attribType(kwargs)", script_callback_language=hou.scriptLanguage.Python, menu_use_token=True) collapsibleFolder.addParmTemplate(attribList) multiparm.addParmTemplate(collapsibleFolder) multiparm.setDefaultValue(1) ptg.appendToFolder(ptg.findFolder("JSON Settings"), multiparm) node.setParmTemplateGroup(ptg) def attribType(kwargs): node = hou.pwd() p = kwargs["parm"] parent = p.parentMultiParm() multiParmIndex = int(kwargs['script_multiparm_index']) menuIndex = int(kwargs['script_value']) container = parent.parmTemplate().parmTemplates()[0] selected = p.menuItems()[menuIndex] a = hou.LabelParmTemplate("test#", f"Testing that this works {multiParmIndex} {selected}") container.addParmTemplate(a) I know what the name should be and I have the correct multiparm index from within kwargs, which is amazing. So how can I put things into the collapsible folders? For the first entry I know I have the settings1 folder and I want to add in that label, but I cannot seem to figure out how to do that.
-
I'm playing around with the filament solver, and I can't seem to get it to work the way they say it does. I am looking to apply a velocity attribute (v) to the points going into the simulation and have them adjust the way it evolves, which the documentation clearly states it can do at the bottom. Is this just broken? What ends up happening is that it pops in the direction of the v attribute on frame 2, but then just progresses as it does without the v attribute at all. Did I just miss a setting somewhere? FilamentQuestionExample.hiplc
-
Brute force square/rectangle packing in non square grids?
Adam Ferestad replied to Pidgy's topic in General Houdini Questions
That is a really interesting solution and I like it. I would like to figure out how to make it minimized though, so there is a minimum total gap space. -
Brute force square/rectangle packing in non square grids?
Adam Ferestad replied to Pidgy's topic in General Houdini Questions
It is completely a packing problem, I was just trying to keep some of the math speak out of my response. I will definitely look at that post you linked to, looks juciy.
