Search the Community
Showing results for tags 'optimization'.
Found 9 results
-
Hi, I would like to know how to achieve and animate something like this in the first video https://www.behance.net/gallery/175765483/LOEHR-x-Spot-Studio? (Screenshot of what I am talking about below) In regard to 1/ which grain properties to adjust 2/ How to achieve clustering some grains as you can see on top - are these separate vellum grain objects set to different seperation rates? 3/ Would be nice to know how you guys go on about optimizing your grain sims.. I run an 12core i9 and it is struggling even with 200K points Much appreciated.

-
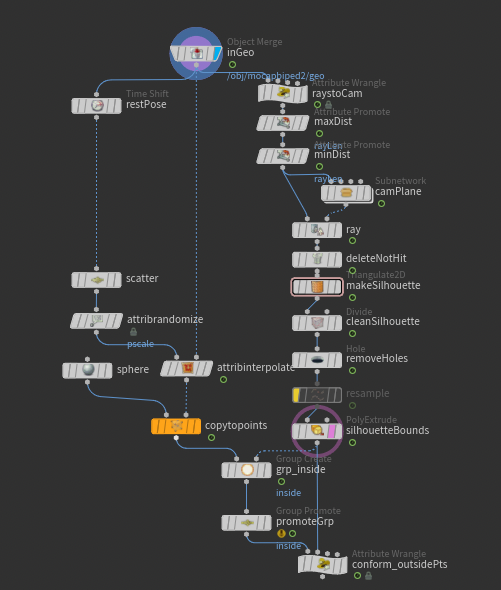
 Hello all, I've been working on this setup for camera-space object silhouettes that will be used to conform/cull objects outside of them. While my setup is functional, it is sluggish...despite me trying to be quite performance conscious. I've prepared a simple example scene for you all to show where I'm at. The main sticking points here are Triangulate2D (slow, but faster than any alternative I've tried), and the group from bounding object (not too bad in the example file, but terrible with more complex silhouettes). I'd also love some help with conforming the points outside the silhouette back into it– the file I attached just does a simple minpos() to the silhouette because it's hard to do better without sacrificing performance. As a result, it fails when limbs get close together or if the geo to be conformed is too low-res. Hopefully that all makes sense! silhouette_setup.hip
Hello all, I've been working on this setup for camera-space object silhouettes that will be used to conform/cull objects outside of them. While my setup is functional, it is sluggish...despite me trying to be quite performance conscious. I've prepared a simple example scene for you all to show where I'm at. The main sticking points here are Triangulate2D (slow, but faster than any alternative I've tried), and the group from bounding object (not too bad in the example file, but terrible with more complex silhouettes). I'd also love some help with conforming the points outside the silhouette back into it– the file I attached just does a simple minpos() to the silhouette because it's hard to do better without sacrificing performance. As a result, it fails when limbs get close together or if the geo to be conformed is too low-res. Hopefully that all makes sense! silhouette_setup.hip

-
So I am working on a project which is requiring me to extract the point numbers from an arbitrary polygonal object. The most pythonic way to do what I am trying to do is this: geo = hou.Geometry() geo.loadFromFile(path/to/my/file.bgeo.sc) primPoints = [[pt.number() for pt in pr.points()] for pr in geo.prims()] I need to maintain the winding order and get it down to just the ints for the point numbers. I have profiled every function in this, and hou.Prim.points() is god awful slow, taking up 16 of 22 seconds on a 1.5M poly, 800k point file. I am trying to find a way to circumvent hou.Prim.points() but nothing is jumping out to me. I have even moved everything into Pandas, which does make working with the data and doing further transformations easier, but I have not gotten any performance increases as it still relies on calling hou.Prim.points() for every primitive. I have contemplated trying to use hou.Geometry.points() and calling hou.Point.prims() to go at it from the other direction, thinking that it might save me some time since the list of points is always shorter than the list of prims, but it loses the winding order, which I need for my use case. Said use case is parsing cached geometry into a custom format for optimized use elsewhere. I have been able to get the performance up to snuff on just about everything else, and will save even more time on later steps thanks to Pandas data management, but this singular step is so sluggish that it just about tanks the whole project. Literally everything else in the pipeline that I am developing is under 4-5 seconds/frame for huge geometry volumes in the pre-process step (which this is part of) and the final end of the process is so fast I'm not even going to talk about it. Literally just this is bogging things down in an untenable way. Pandas code for reference: import pandas as pd geo = hou.Geometry() geo.loadFromFile(path/to/my/file.bgeo.sc) primsSeries = pd.Series(data=geo.prims()) primsSeries = primsSeries.apply(hou.Prim.points) primsSeries = primsSeries.apply(lambda x: list(map(hou.Point.number, x))) The two take virtually identical amounts of time with the pure pythonic one being a couple seconds faster because it is doing the hou.Point.number in the same step as the list generation, whereas the Pandas code currently does it as a secondary step. I'm sure I could include it in the hou.Prim.points apply, but this was mostly separated for profiling to see where all of my speed was going. Does anyone out there have any idea how to bypass hou.Prim.points in this process in favor of something faster or am I 100% stuck?
-
For one of my projects, I am using Vellum hair to simulate my tree branches, but simming gets really slow. To make my curves stiff enough I need to bump substeps to more than 3 and also constraint iterations to more than 50k and obviously, simming gets really slow. I am not sure if I am doing something wrong that I need to bump numbers so high or this is normal to wait so long for vellum simulations? Main settings I am changing are stretch and bend. Before - I made my tree real life scale, but even now, when I scaled it a bit down, I still need to bump my constraint iterations to more than 50K. P.S I have 64GB Ram and Ryzen 3900x, so I am not sure if my hardware is not good enough to sim it.
-
http://patreon.com/posts/33249763 http://gumroad.com/l/houdinisupercharged In this video I will show you some of the inner workings of the context-sensitive rule-based hotkey system that I implemented and one I have been using for a while to speed up my workflow inside Houdini. It's a very light-weight and flexible system that allows an arbitrary number of actions to be assigned to any key, with extensive modifier key and state support (Ctrl, Shift, Alt, Space, LMB, MMB, RMB, selection state). It's deeply integrated into the overlay network editor workflow.
-
- 5
-

-
- optimization
- walkthrough
- (and 11 more)
-
Hey guys, Im rendering a pyro sim around 1-3 mil voxels, im using an environment light and a volume light emitting from the pyroshader. Rendering using PBR with pixel samples 3x3, volume limit 1, noise level, 0.1, volume quality 0.1, volume shadow quality 0.5 and stochastic 8 im not even using motion blur, but one frame is almost taking 1.5 hours. Any ideas how to increase the performance, am i doing some nonos that i missed? the smoke is fairly transparent and the light from the fire is strong.
-
Hi All! Are there any ways to optimise/reduce the file size of Houdini caches. I'm caching a (very small) FLIP fluid sim with a 'File Cache' Node at the moment and each frame is about 100MB. Multiply by 500 frames and that's a BIG cache! - not to mention the time its taking! I am sure it shouldn't be this large considering this is only a very small fluid sim so any tips would be great! I know a lot of people have this issue with sims so hopefully kind people can help us out! Thanks in advance!
-
 This operator allows you to run an OpenCL kernel as part of your SOP network. Depending on the GPU, some operators can be orders of magnitude faster than even VEX. In this case the OpenCL code is 144 times faster than VEX on GTX 970.
This operator allows you to run an OpenCL kernel as part of your SOP network. Depending on the GPU, some operators can be orders of magnitude faster than even VEX. In this case the OpenCL code is 144 times faster than VEX on GTX 970.- 10 replies
-
- 14
-
-
Hey guys, I have this scene with a lot of berries falling. If I select all of the berries and aply a FEM (shelf) at all of it, the action gets very slow and causes closer berries mesh to "fuse" one into another. The reason it gets slow/merge is the solidembed thing. It takes too long to make it for all the berries. My doubt: is there a way to make only one FEM berry and then make muliple copies of it, this way it doesn't have to tetrahedralize all of the berries? Thx, Alvaro





