Search the Community
Showing results for tags 'performance'.
Found 22 results
-
http://www.patreon.com/posts/31506335 Carves out polygons using a point attribute with the ability to define the carve values per primitive using primitive attributes. Pure VEX implementation, 10x faster than the default Carve SOP (compiled). It preserves all available attributes. It supports both open and closed polygons.
- 16 replies
-
- 3
-

-
- procedural
- fx
- (and 9 more)
-
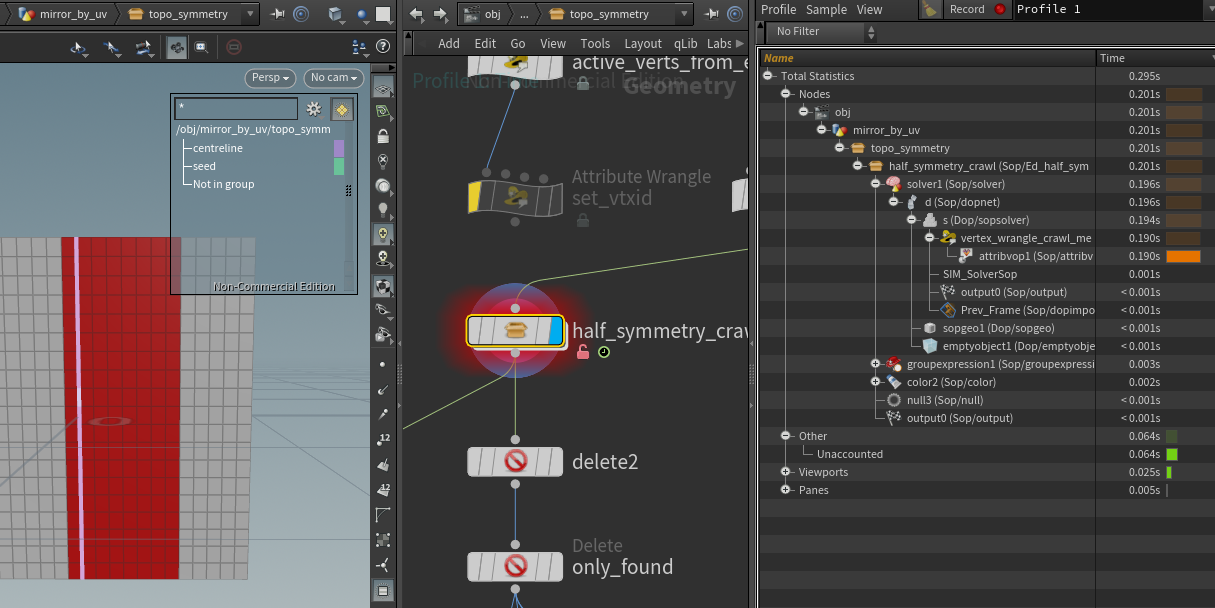
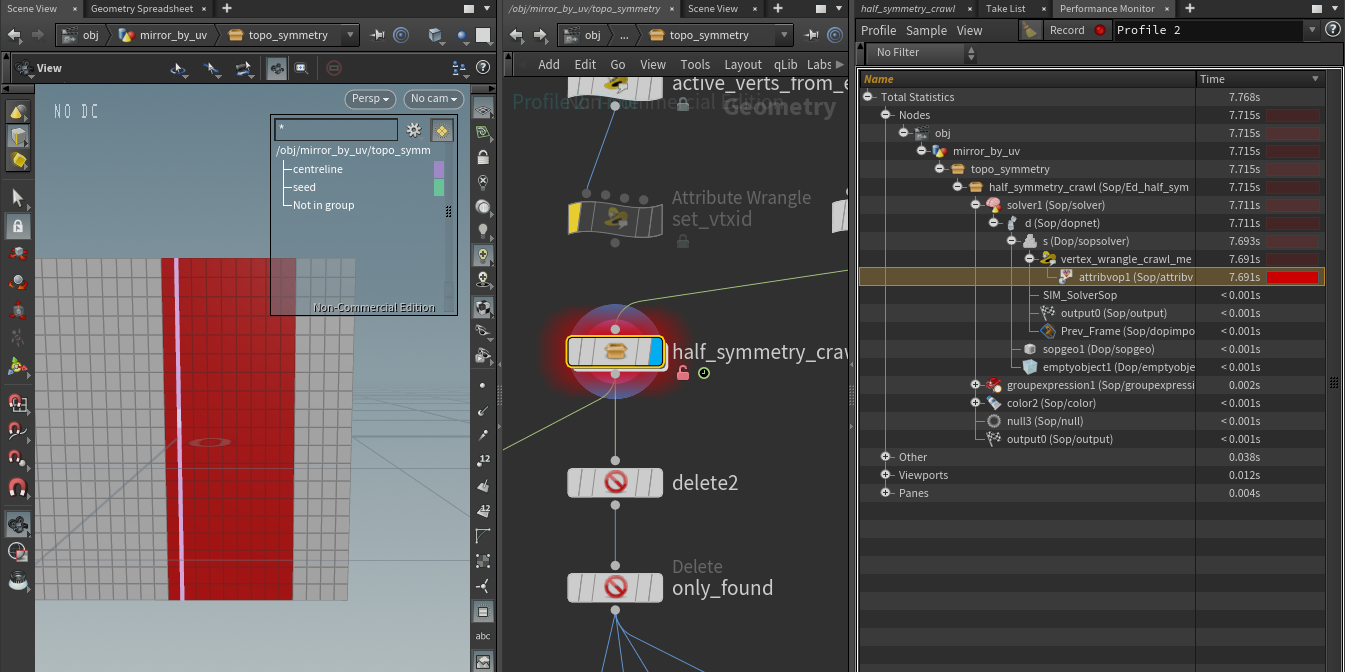
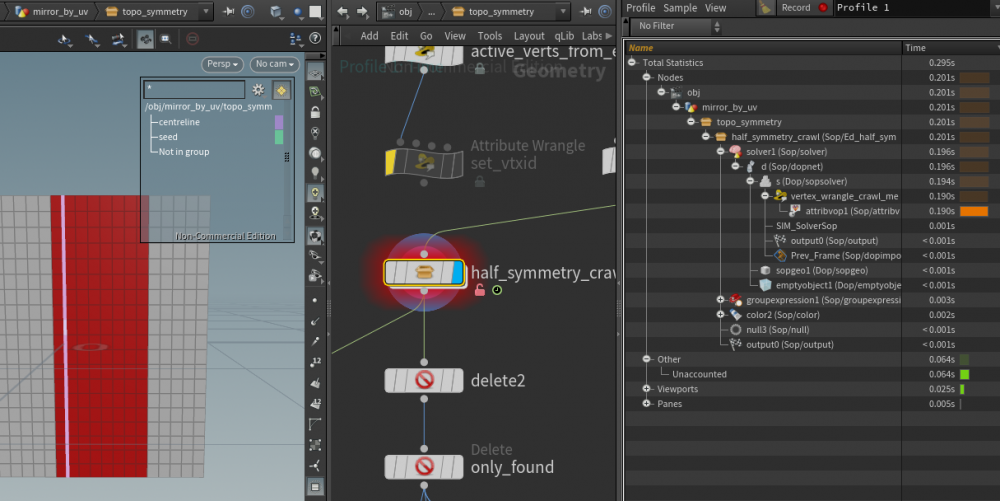
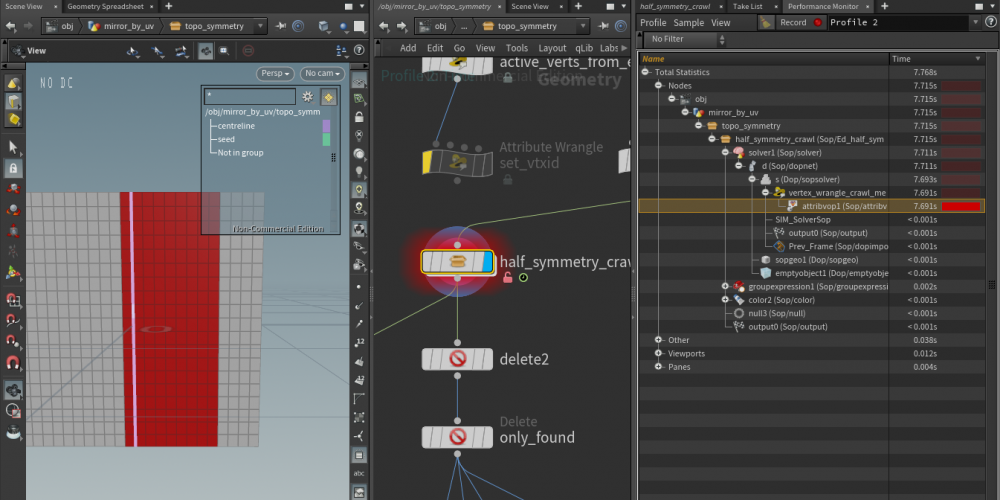
Hi all, I'm running a simple topological vex function over a mesh, designed for topological symmetry. The function below is run in either a compiled for-loop or a SOP solver, I got the same performance from each: function int[] crawlmesh5(int geo; int basehedge; int reversedir; int baseindex; int foundpts[]; int foundprims[]; ){ int newhedges[]; // early out if prim has been processed int primfound = foundprims[hedge_prim(0, basehedge)]; if (primfound){ return newhedges; } //return newvtxes; int localiter = 0; int currenthedge = basehedge; int vtxpt, lookuptwin; do{ if(localiter > 10){ printf("failsafe-break_"); break; } vtxpt = hedge_dstpoint(0, currenthedge); lookuptwin = foundpts[vtxpt]; if(lookuptwin == -1){ setpointattrib(0, "twin", vtxpt, baseindex); //foundpts[vtxpt] = baseindex; baseindex++; } append(newhedges, hedge_nextequiv(0, currenthedge)); if (reversedir){ currenthedge = hedge_prev(0, currenthedge); } else{ currenthedge = hedge_next(0, currenthedge); } localiter++; }while (currenthedge != basehedge); setprimattrib(0, "found", hedge_prim(0, basehedge), 1); return newhedges; } Since wrangles would produce race conditions in the numbering of found points, I'm running this in a detail wrangle, in a manual loop over an array of half edges. foundprims and foundpts are passed by reference and used in place of setting component attributes, and both are saved to and loaded from detail attributes between iterations. When running this function on a grid of 500 points, I get the following performance: On iteration 7: On iteration 8: A slowdown of roughly %8000 . The size of the arrays are not changing across iterations, as far as I can tell nothing is changing other than their content. If anyone has any idea what I'm doing wrong, I will be extremely grateful. Thanks
-
patreon.com/posts/38913618 Subdivision surfaces are piecewise parametric surfaces defined over meshes of arbitrary topology. It's an algorithm that maps from a surface to another more refined surface, where the surface is described as a set of points and a set of polygons with vertices at those points. The resulting surface will always consist of a mesh of quadrilaterals. The most iconic example is to start with a cube and converge to a spherical surface, but not a sphere. The limit Catmull-Clark surface of a cube can never approach an actual sphere, as it's bicubic interpolation and a sphere would be quadric. Catmull-Clark subdivision rules are based on OpenSubdiv with some improvements. It supports closed surfaces, open surfaces, boundaries by open edges or via sub-geometry, open polygons, open polygonal curves, mixed topology and non-manifold geometry. It can handle edge cases where OpenSubdiv fails, or produces undesirable results, i.e. creating gaps between the sub-geometry and the rest of the geometry. One of the biggest improvement over OpenSubdiv is, it preserves all boundaries of sub-geometry, so it doesn't introduce new holes into the input geometry, whereas OpenSubdiv will just break up the geometry, like blasting the sub-geometry, subdividing it and merging both geometries as is. Houdini Catmull-Clark also produces undesirable results in some cases, i.e. mixed topology, where it will either have some points misplaced or just crash Houdini due to the use of sub-geometry (bug pending). Another major improvement is for open polygonal curves, where it will produce a smoother curve, because the default Subdivide SOP will fix the points of the previous iteration in subsequent iterations which produces different results if you subdivide an open polygonal curve 2 times in a single node vs 1 time in 2 nodes, one after the other. This is not the case for polygonal surfaces. VEX Subdivide SOP will apply the same operation at each iteration regardless of topology. All numerical point attributes are interpolated using Catmull-Clark interpolation. Vertex attributes are interpolated using bilinear interpolation like OpenSubdiv. Houdini Catmull-Clark implicitly fuses vertex attributes to be interpolated just like point attributes. Primitive attributes are copied. All groups are preserved except edge groups for performance reasons. Combined VEX code is ~500 lines of code.
-
- 2
-
-
- vex
- performance
- (and 7 more)
-
http://patreon.com/posts/32631275 http://gumroad.com/l/houdinisupercharged In this video I will go through the GUI customizations I did for Houdini 18. So let's get into it.
- 7 replies
-
- 2
-
-
- workflow
- performance
- (and 8 more)
-
Greetings, I have a conventional null and bone hierarchy, using the default nodes provided by Houdini. I would like to replace them, however, with my own HDAs, that have the same exact internal structure, one for bones, another for nulls. The reason is that I want to add extra parameters and scripting to the nulls and bones, and it is easier to do it on HDAs. So far, I haven't seen any difference in performance, but I fear that it will drop, once the size of the hierarchy increases. Is that a valid concern? That a default node will outperform a HDA with identical internal structure, for the sole reason of this being a HDA? Thanks in advance.
-
Hi Houdini friends, Does anyone know if there's a way to just load the metadata of a vdb file without loading the whole file? Trying some load settings on the File sop didn't achieve what I wanted, where "info" and "info bounding box" are both losing the detail attributes which are the metadata fields. Potential options are to use pyopenvdb or inlinecpp with the HDK openvdb classes (?), but maybe there's something I'm missing that is simpler? Thanks so much in advance! - Viola
-
This operator allows you to call a collection of nodes on any data or simply no data (generators). It gives you full control over how the lambda function should be run.
- 3 replies
-
- 6
-
-
- workflow
- productivity
- (and 5 more)
-
Hi there, Are there any benchmarking tests out there that are the most indicative of how houdini will perform running larger simulations? I have read that single core high frequency matters though I also here some people pointing to the new Threadrippers which are mellow in terms of frequency but have high core counts. Looking for a high sample size, objective test that will relate to houdini large scale simulations. Not mantra, not small sims. I wanted to add my current setup to add context. I have an i7 6950x OC'd to 4.2 ghz ( watercooled) with 128gb of 2666 ram. This runs fairly well though I see setups sometimes process faster than my setup. This is all part of me trying to understand everything I can about how houdini manages hardware and how you can tune both hardware and software to each other. I do realize that at a certain point this leaves the single workstation and jumps to a very different process of splitting sims up onto a server to process extremely huge sims. I am more so interested in how to min/max the single workstation. Thanks in advance!
-
 Hey, I took advantage of some of the price drops on GPU's lately with the release of the 20 series cards from Nvidia. I Got an evga 1070ti ftw2 card for 429$( also has a 20$ MIR to drop final cost to 409$). I put this into my machine that has had an evga 1080ti FE card in it since I built it a year and a half ago. I wanted to share the "real world" test results in case anyone else is wondering if it is worth it to pick up another card. The PC is running win10pro, 64gb ddr4 ram, intel i7 6850k 3.6ghz, primary drive is a samsung 960 evo m.2 ssd and a secondary crucial ssd, 1000 watt evga gold G3 psu, Houdini 16.5.268 and redshift 2.5.48 ( i think ) etc... I ran a redshift test on a scene that is a decent size pyro sim, rendered 60 frames at full HD with fairly hq setting. With just the 1080ti in the pc, the render took 38min17seconds. With the addition of the 1070ti, the render took 25min26seconds for the 60 frame sequence. Adding the second card took almost 13 minutes of the sequence render time. I would say it is worth the roughly $400 bucks. With the option of enabling/disabling gpu's in the redshift plugin options, I ran a single frame of the render and here was the result: with just the 1080ti - 26 seconds for the first frame. With just the 1070ti - 34s, with a little boost to the gpu settings on the 1070ti using the evga overclock software - 32 seconds( not enough for me to want to keep it overclocked beyond how it arrived). With both gpu's enabled - 15 seconds. I think I would be willing to buy another 1070ti while the sale/rebate is going on if it will reduce the render time a further 13 minutes. I'm assuming it would, but maybe I'm not adding something up right here. If adding one 1070ti to the machine cut 13 minutes off the render, wouldn't the addition of another 1070ti take another 13 minutes off the render time.? It would be incredible to drop the test sequence render time down from 38 min to 12 min for roughly $800 in hardware upgrades.! I ran all the PC's parts through a component checker online and even If I add a 3rd card, it should still have about a 100watts of buffer on the 1000w psu. Would probably want to add some more/better case fans if increasing the GPU count from one to three.! Anyways, thats what adding an extra card did for me. E
Hey, I took advantage of some of the price drops on GPU's lately with the release of the 20 series cards from Nvidia. I Got an evga 1070ti ftw2 card for 429$( also has a 20$ MIR to drop final cost to 409$). I put this into my machine that has had an evga 1080ti FE card in it since I built it a year and a half ago. I wanted to share the "real world" test results in case anyone else is wondering if it is worth it to pick up another card. The PC is running win10pro, 64gb ddr4 ram, intel i7 6850k 3.6ghz, primary drive is a samsung 960 evo m.2 ssd and a secondary crucial ssd, 1000 watt evga gold G3 psu, Houdini 16.5.268 and redshift 2.5.48 ( i think ) etc... I ran a redshift test on a scene that is a decent size pyro sim, rendered 60 frames at full HD with fairly hq setting. With just the 1080ti in the pc, the render took 38min17seconds. With the addition of the 1070ti, the render took 25min26seconds for the 60 frame sequence. Adding the second card took almost 13 minutes of the sequence render time. I would say it is worth the roughly $400 bucks. With the option of enabling/disabling gpu's in the redshift plugin options, I ran a single frame of the render and here was the result: with just the 1080ti - 26 seconds for the first frame. With just the 1070ti - 34s, with a little boost to the gpu settings on the 1070ti using the evga overclock software - 32 seconds( not enough for me to want to keep it overclocked beyond how it arrived). With both gpu's enabled - 15 seconds. I think I would be willing to buy another 1070ti while the sale/rebate is going on if it will reduce the render time a further 13 minutes. I'm assuming it would, but maybe I'm not adding something up right here. If adding one 1070ti to the machine cut 13 minutes off the render, wouldn't the addition of another 1070ti take another 13 minutes off the render time.? It would be incredible to drop the test sequence render time down from 38 min to 12 min for roughly $800 in hardware upgrades.! I ran all the PC's parts through a component checker online and even If I add a 3rd card, it should still have about a 100watts of buffer on the 1000w psu. Would probably want to add some more/better case fans if increasing the GPU count from one to three.! Anyways, thats what adding an extra card did for me. E -
Hi all, we recently purchased Houdini at my workplace, and I'm noticing a slight issue when saving my scenes to our network drive. Right now I'm working on a .hip file that's about 20MB. Saving it to any of my local disks is done in seconds. Copying the same file from my local drive to the network only takes a second as well. Saving it to our network drive directly, on the other hand, I can watch the file size slowly grow and it takes about 60 seconds to complete! So I am guessing it has something to do with how Houdini does the file writing. I don't see this happen to any file caches etc. Only when saving the scene file. Unfortunately for us, our data center is not in-house. It's located a few blocks away. So I am guessing it has something to do with how network traffic is routed over - and that a lot of small writes (compared to a large file copy) is slow. Has anyone else experienced this? Are there any workaround. I.e. forcing Houdini to save locally and copy the file? I know 3dsMax and other software normally handles files this way.
-
Creating a node takes ages. What could be the problem that is making it so slow? It did this after the latest update (updated 15.5.632 to 15.5.674) Please note that we already tried to install versions as far back as 15.0 and until the latest version of 15.5. The problem keeps occurring even without virus scanners and windows defender being turned off. It also doesn't matter if it is installed on a SDD or on a HDD and all the drivers are up to date. Even if all the preferences have been deleted (in the documents directory) it stays the same and it also doesn't matter on which Houdini License server it's running: in Standalone mode or not. I'm running out of ideas to what the problem could be. If you know the solution or have an idea what it could be, let me know! Please ignore the audio in the example video below, it is in a noisy classroom with students discussing different nodes (not related to what you see, you can watch without audio)
-
 This operator allows you to run an OpenCL kernel as part of your SOP network. Depending on the GPU, some operators can be orders of magnitude faster than even VEX. In this case the OpenCL code is 144 times faster than VEX on GTX 970.
This operator allows you to run an OpenCL kernel as part of your SOP network. Depending on the GPU, some operators can be orders of magnitude faster than even VEX. In this case the OpenCL code is 144 times faster than VEX on GTX 970.- 10 replies
-
- 14
-
-
Volume convolution on the GPU using OpenCL. For 27M voxels using 100 iterations, OpenCL is 650 times faster than C++ and 12525 times faster than VEX.
- 15 replies
-
- 3
-
-
- opencl
- performance
- (and 6 more)
-
Hello people! I am buying a laptop workstation to use while traveling for a few months later this year and I don't know if I should buy a laptop with a Quadro or a GTX card in it. What are the pros & cons? (price excluded) Does Houdini run better in general on Quadro cards? Also, feel free to drop some laptop recommendations if you have any! I've got my eyes on a Dell Precision 7710. Best regards, //Simon
-
Hi all, Completely new to Houdini and this forum! I am Cinema4D-er learning Houdini on a brand spanking new PC. It's also my first build so not-so-bright choices may have been made... It seems my viewport/perspective view is taking up so much time (Red-zone on the Performance Monitor). Figured I'd start by checking my hardware, so please judge my build for anything that is off... (Don't judge me ) Thanks for your help i7-7700K Asus Prime Z270-A Corsaie LPX DDR4-2133 MSI GeForce GTX 1060
-
First things first: – This is not a “why Mantra is so slow” topic. In fact, Mantra is my first renderer, so until now, for what I read, it seems pretty fast and good. – I came from a digital product design background and I’m really new to 3d and Houdini. – I’m using a MacBook Pro for learning which I know its definitely not the best machine to work with 3d stuffs. (Specs: Mid 2012, 2.3Ghz i7, 8GB RAM, GeForce GT 650M 1GB) So after this (not so happy) presentation, lets talk about my problem: I was doing a tutorial from Niels Prayer about how to make a geometry react from an audio file and after that I've tried to render a sequence of 860x540 images. I waited 14 long hours for about 12 secs of video. Is this normal for my computer specs? I forgot to cache the geo, but I don’t know if this could be a great factor to get a faster render, could be? I've read some topics about Mantra settings from Odforce and SideFX forum and found some interesting tips about how to get better and faster rendering trying to get down the pixel sample values, increase the max ray samples and tweak the noise level to an acceptable value. So I’ve attached a hip file with my Mantra settings, and my machine can render this frame in about 3:13 min. This is current the best I can do in terms of speed and quality. Do you guys can check it out my file and see what I can do to get a faster render? Please feel free to hit me with tips on how to get the best of Mantra and Houdini in general. Thanks a lot. Cheers, render-test.zip _render_test_1.exr
-
Hi, with several scenes I have alwas the same problem. I start simulation of a volume or flip sim what works fine for the first few frames. Then the cpu usage drops down and only one core is used most of the time. For every frame, the cpu usage goes up for a few seconds only, then it drops again. So I suppose it has to do something with my general setup. My current simulation is a breaking bottle with liquid what looks like in the attached image. I'd really appreciate if anyone could have a look at the scene and give me a hint what I'm doing wrong. The file is a bit larger (23 mb) so I placed it here: bottle archive Thanks for any ideas.

-
Hello, I was recently testing a flip simulation on a workstation with dual xeon 2630 v4 processors 10 cores each clocked at 2.2 GHZ, to my astonishment my laptops quadcore 4770HQ @2.2GHZ delivered ,not the same, but better FLIP simulation times. Can anyone explain to me why this is. I heard someone tell me something about threading. Can someone give me some insight on which nodes are multithreaded. with the smoke solver its stranger when my division size is higher like 0.2 the quadcore processor absolutely destroys the dual xeon, flying past the simulation. but when I start reducing that division size the xeon processors start to catch up and eventually when I am at a final render division size the xeons are ahead of the quadcore. Also when I cache out a simulation and check task manager when the cache is somewhere in the middle of the simulation(presumably where the flip simulation has the most particles to solve), task manager shows the cpu hovering around 2-3 %.
-
Smoothing geometry on the GPU using OpenCL. In VEX it has to be done in 2 steps where the same thing can be achieved in OpenCL in one step using barriers [khronos.org]. For a 822K polygon model, it's over 500 times faster than VEX on GTX 970 for 1000 iterations, and over 600 times faster for 10K iterations. Timings are recorded separately as there seems to be some overhead when running them one after another. Special thanks to SESI.
-
The most powerful wrangle operator due to the sheer fire power of the HDK. Performance increase can vary from a few times to thousands of times depending on the scenario.
-
Hi there! I have a rapid question... there is some particular setting/option or check in Houdini (15) for improve the peformance with hadware? Actually I have: AMD FX 8350 @ 4GHz 32 GB of Ram ddr3 GTX 970 4GB (especially on this section) ssd pro evo OS: win 7 I see some time the "auto-update" of viewport is a few slow.... in alternative is change more the performance from 970 to 980TI or change more if I pass to Linux (fedora/ubunto or centOS) ? Thank you for now Matteo
-
Hi ! I got an office space where i have the machines /server /fast interneto..when working past dinner time or at unreasonable hours (often) I do it from home, by using RDC (remote desktop connection) on win7, it works well with most apps, but Houdini wont run trough it. It runs using TeamViewer,,,but is sloooooooooooow. I have a gaming video card at home and nothing too fancy at the office, which works fine, i don't know if this is a driver issue (got latest nvidia drivers) or some configuration i can change in houdini? thanks O/.